Data Access and Caching
Panopticon assumes in general that data is never at rest and too big to be simply loaded into memory. The data can either be subscribed against or polled (automatically refreshed on a defined period).
This means either:
- Load Subset of Data in Memory
- Load Summary and Parameterized Detail Views
- ROLAP (Dynamically explore datasets)
Consequently, for direct access, Panopticon is only as fast as the underlying data platform, or the refreshing of result set caches.
When data is not changing on a timely basis, such as a daily updated data warehouse, there is the additional option of retrieving data into a data store.
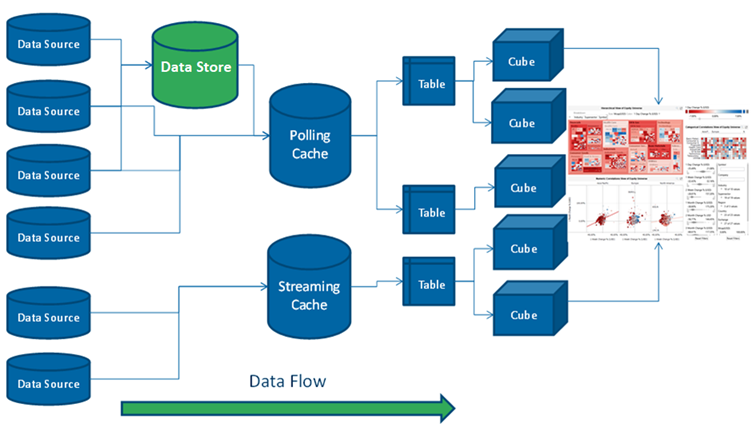
Consequently:
- Only required data is retrieved. Majority of the data stays in the underlying data sources
- Typically aggregated, conflated, filtered data is retrieved
- Behind each dashboard part (visualization) is a micro-cube
- Each cube is designed for streaming real time updates
- Behind each cube is a real-time data table (also powering filters)
- Behind each data table is a resultset cache
- Behind the cache is the underlying data repository
- Caches can be loaded on the fly, or pre-loaded on a periodic basis
- All caching is optional
- Consequently, data access is either:
- Work Directly against underlying sources (either Exploratory Analysis (ROLAP), Or Pre-Defined Parameterised Views)
- Import data into the Data Store
Usage is typically Hybrid. Based on the characteristics of the underlying data, you choose whether to import to Data Store and load, or query directly.
This is to cater for real world data landscapes, where different data has different data retrieval latency characteristics, and different timeliness; and where there is too much data to simply load all into memory.
(c) 2013-2024 Altair Engineering Inc. All Rights Reserved.