Client/Server Architecture
All of Altair Accelerator's products are based on a client/server architecture to support concurrent activities, team coordination, distributed data management, and distributed processing. The program vovserver runs in the background as a service to implement the main product features. It is the server.
Other programs may run as background daemons to help vovserver provide specialized features or actions. The set of daemon programs form a working server system that may be referred to as the vovserver.
The total number of clients that can connect concurrently to vovserver depends on the maximum available "descriptors", which can reach up to thousands for modern hardware.
- Client Type
- Description
- Tools/Jobs
- The ability of jobs to connect to the vovserver at runtime is a key element of the vovserver approach. Through a number of "integration techniques", programs in a job, such as compilers, simulators, UNIX utilities, renderers or other tools, can connect to the vovserver to declare their inputs and outputs, so that the vovserver can maintain the dependency graph and the flow data.
- Users
- The users can connect to the server to query and modify the design flow
data by using Command Line Interface (CLI) commands, by using the
desktop GUI console, by using the web application console via a web
browser, or by running scripts that use the API commands.Note: A browser can also be considered a client.
- Taskers
- These are helper clients that run on remote machines to provide access to computing resources to run jobs.
- Proxies
- Provide the server with information about external databases. These clients are rarely used. All essential databases, such as file systems, are internally supported by the vovserver.
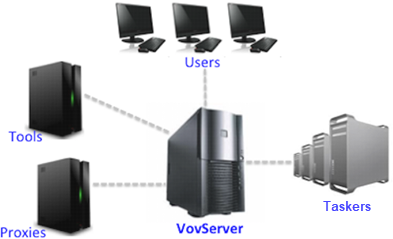
Figure 1. The vovserver can Interact with Various Types of Clients
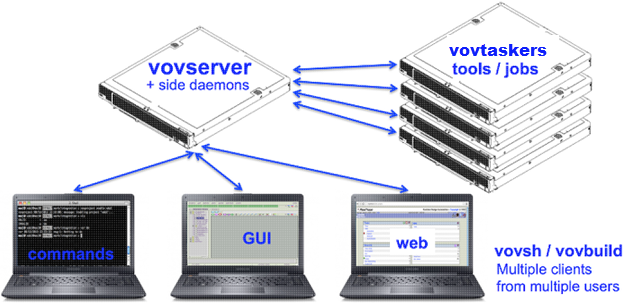
Figure 2.
- The main vovserver system that runs vovserver and other daemons, which manages the graph of dependencies, and jobs to schedule and run.
- The multiple vovtasker hosts that typically run on remote machines, which run the jobs and tools.
- Clients running on various machines, which provide access to the vovserver system by running a shell to call CLI programs, or running a desktop console GUI, or running a web browser to interact with the web console application of vovserver. These interact with vovserver to control the execution of job.
Relationship between FlowTracer, Accelerator, and Monitor
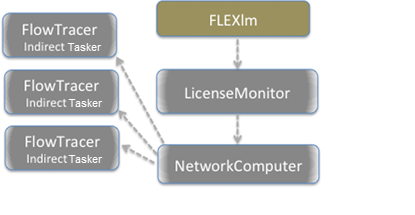
Figure 3. The Interaction of FlowTracer with Accelerator
Monitor and Accelerator are two other components of the VOV system. These components are not required to run FlowTracer, but are often used in conjunction with FlowTracer.
Both Monitor and Accelerator use the same architecture as FlowTracer. Monitor focuses on reporting of license utilization data, Accelerator focuses on efficient execution of jobs using available computing resources, while FlowTracer uses flow management techniques to submit a clean workload to the compute farm.