
HS-1705: 簡単なフィットスタディ
空間充填のDOEスタディをセットアップし、続いてフィットスタディをセットアップする方法について学習します。
DOEの実行
-
DOEを追加します。
-
スタディ仕様を定義します。
- ステップに進みます。
- ワークエリア内でモードをHammersleyにセットします。
- Apply(適用)をクリックします。
-
タスクを評価します。
- ステップに進みます。
-
Area 2とResponse 1、Response 2の間の依存を示したプロットを確認します。
-
散布図を比較し、設計空間を通して一様に分布しているかどうかを確認します。
図 1. 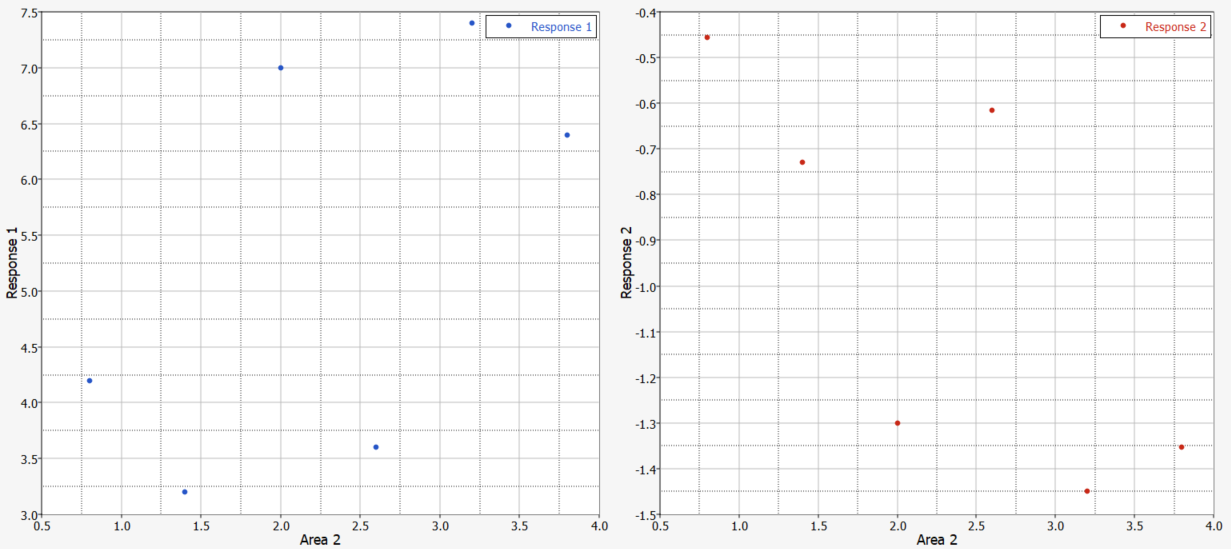
-
散布図を比較し、設計空間を通して一様に分布しているかどうかを確認します。
フィットスタディの実行
-
Fit(フィット)を追加します。
- Explorer(エクスプローラ)内で右クリックし、コンテキストメニューからAdd(追加)を選択します。
- Add(追加)ダイアログで、Fit Existing DataFit(既存データフィット)とSetup(セットアップ)を選択し、OKをクリックします。
-
スタディ仕様を定義します。
- Specifications(スタディ仕様)タブをクリックします。
- ワークエリアのFit Type(近似手法)列で、両方の出力応答にLeast Squares Regression(最小二乗法) (LSR)を選択します。
- Apply(適用)をクリックします。
図 2. 
-
マトリックスを定義します。
- ステップに進みます。
- ワークエリアで、Origin(原点)をApproach(アプローチ)に設定します。
- Origin Settings(原点設定)に、DOE 2を選択します。
- 適用をクリックします。
図 3. 
-
タスクを評価します。
- ステップに進みます。
- Evaluate Tasks(計算実行)をクリックします。
-
結果をポスト処理します。
-
Diagnostics(診断)タブをクリックし、フィットの全体的な品質を確認します。
フィットの相対的な品質を示す数値がいくつか表示されます。決定係数の値は、フィットによって説明されえるデータ内の分散のパーセンテージとして解釈できます。
Response_1については、フィットはデータ分散の100%を捕捉しています。Response_1は実際線形関数であし、1次回帰は誤差なしで実際のデータと一致するため、これは理に適っています。Response_2については、フィットが分散の約90%を説明していることが示されています。図 4. 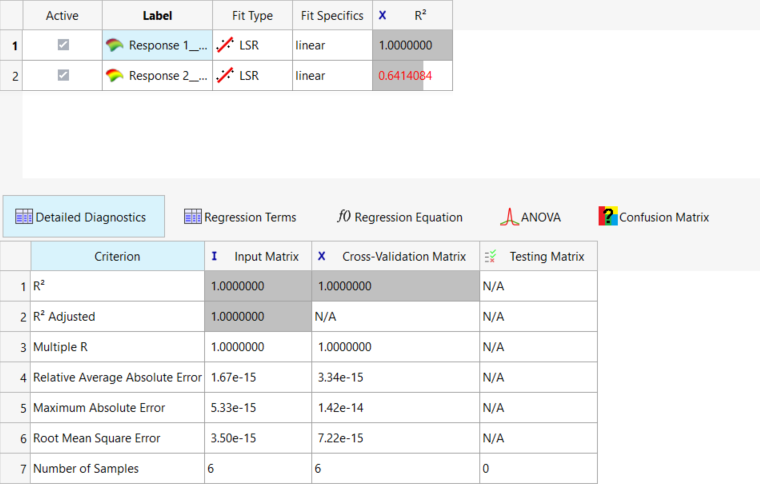
-
Diagnostics(診断)タブをクリックし、フィットの全体的な品質を確認します。
-
Specifications(スタディ仕様)ステップに戻り、出力応答の応答について許容可能なフィッティングを見出すまで別の手法を試してください。
1次の最小自乗では、データの分散のほとんどを説明するフィットを得ますが、これは比較的大きい予測誤差を有します。