HS-2201:Excelスプレッドシートからの既存設計データのLookupモデルとの使用
.csvファイル内の設計データのみが使用可能な(すなわちシミュレーションモデルは存在しない)ケースについて最適化スタディを実行する方法について学習します。
本チュートリアルの目的は、study_data.csvファイル内の設計を使ってフィット(近似)を生成し、それを用いて最適化スタディを実行することです。
第1列および第2列には各設計についての2つの入力変数の値、第3列と第4列には過去に実行されたDOEスタディの結果が含まれています。16の設計が評価されています。
スタディのセットアップの実行
- HyperStudyを開始します。
-
以下の方法で新規スタディを開始します:
- メニューバーから、をクリックします。
- リボン上で
 をクリックします。
をクリックします。
- Add Study(スタディの追加)ダイアログでスタディの名前を入力し、スタディの場所を選んでOKをクリックします。
- Define Models(モデルの定義)ステップに進みます。
-
Lookupモデルを追加します。
- Add Model(モデルを追加)をクリックします。
- Add(追加)ダイアログでLookupを選択し、OKをクリックします。
-
ワークエリアのResource(リソース)列で、
 をクリックします。
をクリックします。
- HyperStudy - Load model resource(モデルリソースの読み込み)ダイアログで作業ディレクトリに進み、study_data.csvファイルを開きます。
-
変数をインポートします。
- Import Variables(変数のインポート)をクリックします。
- Import Variables(変数のインポート)ダイアログで、Number of design variables(設計変数の数)欄に2と入力します。
- OKをクリックします。
図 1. 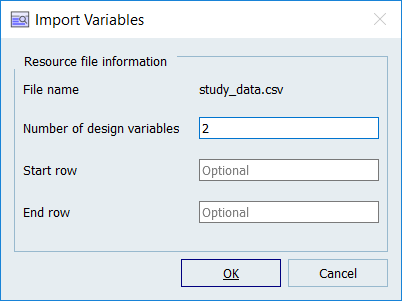
- Define Input Variables(入力変数の定義)ステップに進みます。
-
study_data.csvファイルからインポートした2つの入力変数を確認します。
図 2. 
ベースランの実行
- Test Models(モデルをテスト)ステップに進みます。
-
Run Definition(計算実行)をクリックします。
スタディのDirectory(ディレクトリ)内に、approaches/setup_1-def/ディレクトリが作成されます。approaches/setup_1-def/run__00001/m_1には、ベースランの結果である入力ファイルが含まれます。
出力応答の確認
- Define Output Responses(出力応答の定義)パネルに進みます。
-
study.csvファイルからインポートした2つの出力応答を確認します。
図 3. 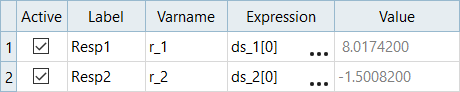
CSVからのDOE結果のインポート
-
DOEを追加します。
- ステップに進みます。
- ワークエリア内でMode(モード)をRun Matrix(実行マトリックス)にセットします。
-
Settings(セッティング)タブで、Matrix File(マトリックスファイル)欄のをクリックします。
-
Openダイアログで、作業ディレクトリに進み、study_data.csvファイルを開きます。
図 4. 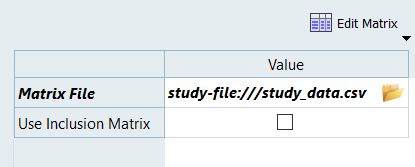
- Apply(適用)をクリックします。
- ステップに進みます。
- Evaluate Tasks(計算実行)をクリックします。
フィットスタディの実行
-
Fit(フィット)を追加します。
- Explorer(エクスプローラ)内で右クリックし、コンテキストメニューからAdd(追加)を選択します。
- Add(追加)ダイアログで、Fit Existing DataFit(既存データフィット)とSetup(セットアップ)を選択し、OKをクリックします。
-
マトリックスをインポートします。
- ステップに進みます。
- Add Matrix(マトリックスの追加)をクリックします。
- Import Matrix(マトリックスのインポート)をクリックします。
-
スタディ仕様を定義します。
図 5. 
-
タスクを評価します。
- ステップに進みます。
- Evaluate Tasks(計算実行)をクリックします。
- ステップに進みます。
-
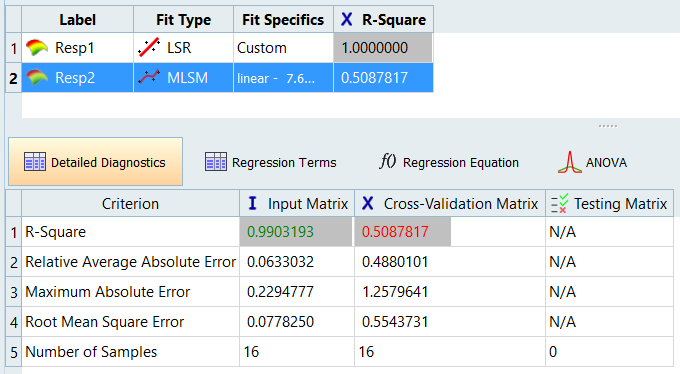
Diagnostics(診断)タブをクリックします。
Resp1はカスタム項を用いたLSRの使用で最良のフィットになり、Regression Terms(回帰式の項)タブは、線形項のみが必要であることを示しています。Resp2はMLSMの使用で最良の結果になります。Resp2については、入力マトリックスに基づいた決定係数の値が、モデルの精度が非常に良好であることを示しています。交差検証の値はあまり良くありませんが、データ量がより多くなると効果的である可能性があります。これは、モデルの精度がポイント群に大きく依存するためです。入力セットからポイントを削除すると、フィットの予測が大きく変わる可能性があります。
図 6.