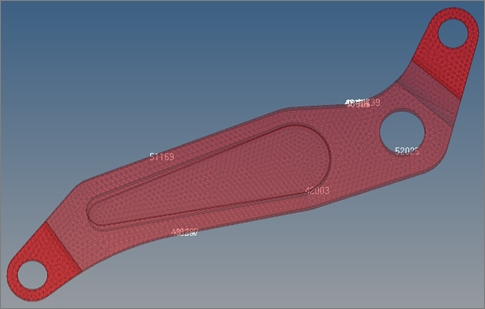
HS-3000: フィット手法の比較: アームモデルの近似
チュートリアルで紹介されたアームモデルの出力応答の近似を作成し、異なるフィット手法間における差異について確認する方法について学習します。
HS-2000: DOE化手法の比較: アームモデルのスタディでは、9つの入力変数ではなく6つの入力変数で同程度に効果的にスタディを継続できることが分かりました。他の変数は出力応答にそれほどの影響を及ぼさないためです。これは、計算の負荷を軽減します。
- Length1: Lower Bound = -0.5, Initial Bound = 0.0, Upper Bound = 2.0
- Length2:Lower Bound = 0.0, Initial Bound = 0.0, Upper Bound = 2.0
- Length3:Lower Bound = -1.0, Initial Bound = 0.0, Upper Bound = 1.0
- Length4:Lower Bound = -1.0, Initial Bound = 0.0, Upper Bound = 1.0
- Length5:Lower Bound = -1.0, Initial Bound = 0.0, Upper Bound = 1.0
- Height: Lower Bound = -1.0, Initial Bound = 0.0, Upper Bound = 1.0
MELS DOEスタディの実行
このステップでは、Modified Extensible Lattice Sequence(修正済み拡張格子配列) (Mels) DOEを作成します。このマトリックスを使って、両方の出力応答についてフィットを作成します。
MELSは、サンプリングポイントの集中や空白を最小限にすることによってポイント群を均等に分散させるために設計された空間充填DOE手法です。N個の変数を有する2次多項式を作成するのに必要な最小限のポイント数は、1.1*(N + 1)*(N + 2)/2 です。
代用モデルとして使用される近似を作成するために、入力マトリックスとして機能する特定のDOEを実行する必要があります。MELSなど、応答曲面作成で使用されるにふさわしいDOEを実行しなくてはなりません。
-
DOEを追加します。
-
入力変数を修正します。
- ステップに進みます。
- ワークエリアのActive(アクティブ)列で、radius_1、radius_2、およびradius_3のチェックマークを外します。
図 1. 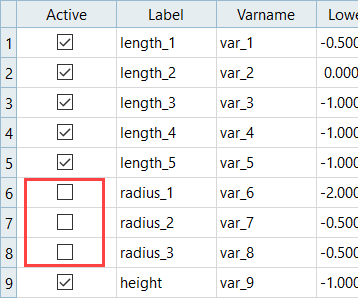
-
スタディ仕様を定義します。
- ステップに進みます。
- ワークエリアで、Modes(モード)をModified Extensible Lattice Sequence (修正済み拡張格子配列)(MELS)にセットします。実行の数を31に設定します。
- Settings(セッティング)タブで、Number of Runs(実行の数)が31となっていることを確認します。
- Apply(適用)をクリックします。
-
タスクを評価します。
- ステップに進みます。
- Evaluate Tasks(計算実行)をクリックします。
- ステップに進みます。
-
Scatter(散布図)タブをクリックし、MELS DOEからの結果の2D散布図を確認します。
図 2. 31のラン(length_1 vs. length_2)のMELS DOEの典型的なサンプリング. この図は、6つの側面に分散された31個のポイントの2次元平面への投影です。 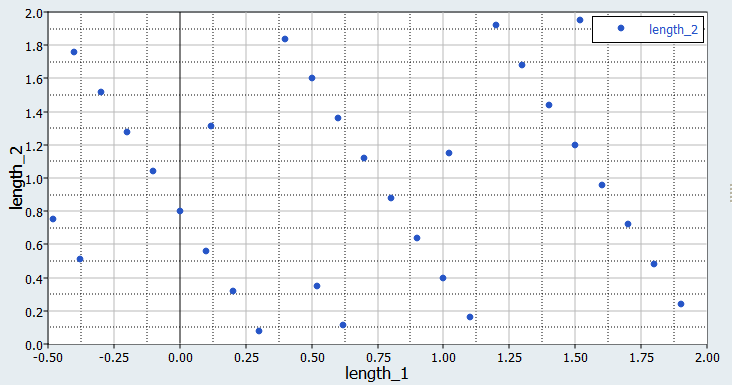
オプション:より少ない実行数でのDOEの実行
このステップではオプションとして、フィットアプローチでの検証マトリックスとして使用するために、より少ない実行数で2つ目のDOEを作成します。
本チュートリアルでは、検証マトリックスの作成に、Hammersleyを使用します。
-
DOEを追加します。
-
スタディ仕様を定義します。
-
Settings(セッティング)タブで、Number of Runs(実行の数)を12に変更します。
図 3. 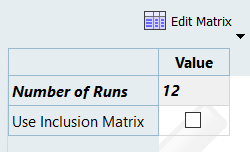
-
Settings(セッティング)タブで、Number of Runs(実行の数)を12に変更します。
-
タスクを評価します。
- ステップに進みます。
- Evaluate Tasks(計算実行)をクリックします。
フィットスタディの実行
このステップでは、MELS DOEからの31のランを入力マトリックスとして、また、Hammersley DOEからの12のランを検証マトリックスとして使用し、最小自乗回帰法(LSR)、移動最小自乗法(MLSM)、HyperKriging近似(HK)および放射基底関数(RBF)を用いて4つのフィットを作成します。
-
Fit(フィット)を追加します。
- Explorer(エクスプローラ)内で右クリックし、コンテキストメニューからAdd(追加)を選択します。
- Add(追加)ダイアログで、Fit Existing DataFit(既存データフィット)とSetup(セットアップ)を選択し、OKをクリックします。
-
マトリックスをインポートします。
- ステップに進みます。
- Add Matrix(マトリックスの追加)を2回クリックします。
- ワークエリアで、図 4に示されるオプションを選択し、Fit Matrix 1とFit Matrix 2を定義します。
- 適用(適用)をクリックします。
図 4. 
-
スタディ仕様を定義します。
-
タスクを評価します。
- ステップに進みます。
- Evaluate Tasks(計算実行)をクリックします。
- ステップに進みます。
-
Scatter(散布図)タブをクリックし、元のMax_Stress出力応答とフィットMax_Stressを比較します。
散布図は、フィットの精度を表します。ポイント群が対角線に近いほど、フィットは良好です。Max_Stress vs Max_Stress_LSRのプロットでは、分散したポイント群も一部見られます。これは、フィットが部分的に精確ではないことを表しています。それに対し、Max_Stress vs Max_Stress_MLSMのプロットは、より対角線に沿っています。これは、Max_Stressについてフィットの精度が高いことを示しています。
散布図を使ったHyperKrigingとRadial Basis Functionの比較は行いません。これは、結果が誤っている可能性があるためです。HyperKrigingとRadial Basis Functionはデフォルトでポイントそのものを通過するため、元の出力応答とフィットの出力応答を比較する散布図は直線となります。しかしながら、これは必ずしも、フィットが良好な予測能力を有することを意味しません。図 5. Max_stressとMax_stress、LSRの比較 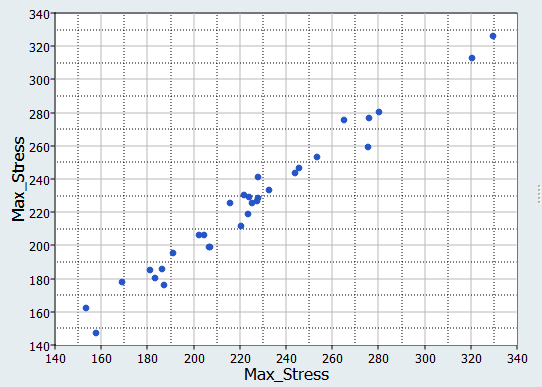
図 6. Max_stressとMax_stress、MLSMの比較 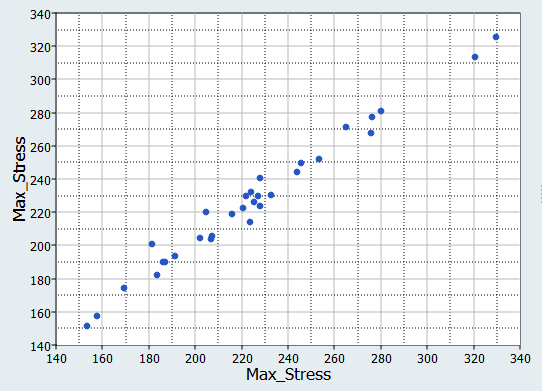
-
Diagnostics(診断)タブをクリックし、フィットスタディの診断を確認します。
決定係数値は、応答データの平均値周りのばらつきがどれだけ捕捉されているかの尺度となります。モデルが既知の値を完全に予測している場合、決定係数は可能である最大の値である1.0を示します。
図 7. Max_Stress、LSRの診断 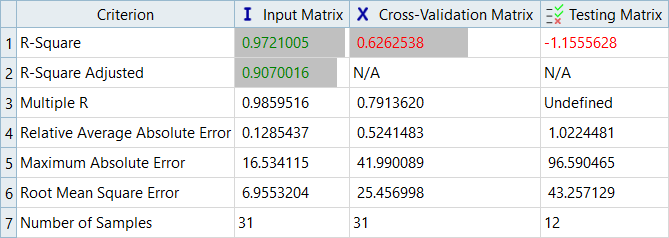
図 8. Max_Stress、MLSMの診断 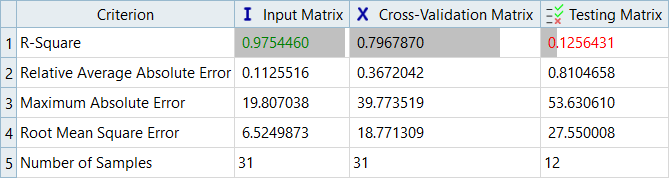
HyperKrigingとRadial Basis Functionでの入力マトリックスの決定係数値は意味を持ちません。これは、実行がデータポイントそのものを通過するために、値が1.0となるためです。値が1.0であっても、これは、フィットが精確であることを意味してはいません。HyperKrigingとRadial Basis Functionでは、意味のある診断値は、交差検証マトリックスと検証マトリックスのみです。図 9. Max_Stress、HKの診断 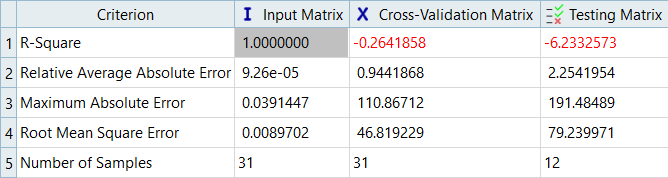
図 10. Max_Stress、RBFの診断 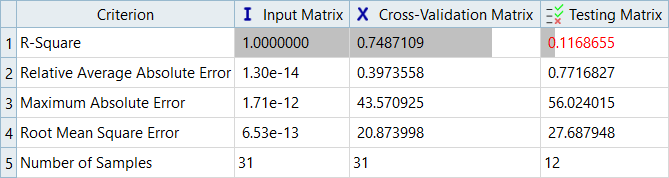
-
Residuals(残差)タブをクリックし、元の出力応答とフィットの出力応答との間の誤差および誤差(%)を、それぞれの入力および検証マトリックスの各実行について確認します。
図 11. Max_Stress、LSRの入力マトリックスの残差 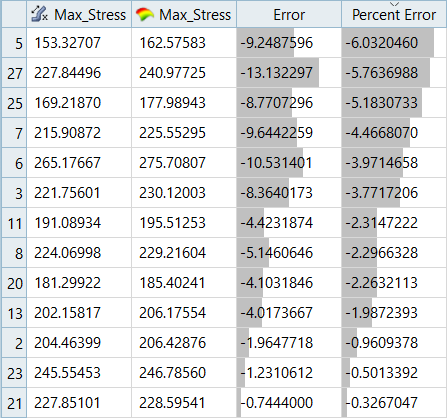
図 12. Max_Stress、LSRのテストマトリックスの残差 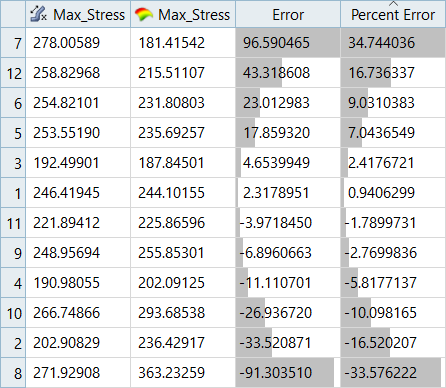
入力マトリックスの残差の誤差は、Least Square RegressionではMoving Least Square Methodと比べてやや小さくなっていますが、テストマトリックスの残差の誤差はMoving Least Square Methodのほうがかなり小さくなっています。図 13. Max_Stress、MLSMの入力マトリックスの残差 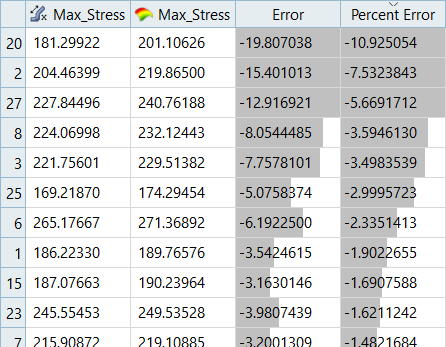
図 14. Max_Stress、MLSMのテストマトリックスの残差 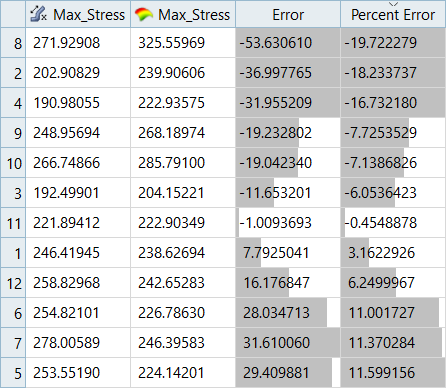
入力マトリックスの残差は、HyperKrigingとRadial Basis Functionでは、下のテストマトリックスの残差で示すとおり、意味を持ちません。図 15. Max_Stress、HKのテストマトリックスの残差 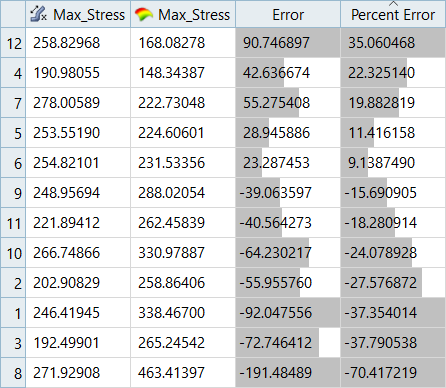
図 16. Max_Stress、RBFのテストマトリックスの残差 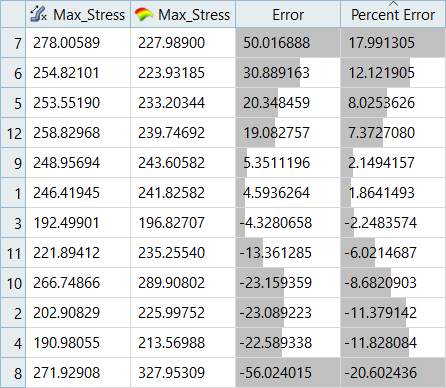
フィットの比較
入力およびテストマトリックスの誤差の最大パーセントの確認。
| LSR(交互作用回帰モデル) | MLSM | HK | RBF | |
|---|---|---|---|---|
| Max_Disp | -1.18% | -2.79% | - | - |
| Max_Stress | -6.72% | -10.92% | - | - |
| LSR(交互作用回帰モデル) | MLSM | HK | RBF | |
|---|---|---|---|---|
| Max_Disp | 7.26% | -3.00% | 9.57% | -2.45% |
| Max_Stress | 34.74% | -19.72% | 35.06% | 17.99% |
Max_Dispの誤差(%)はMax_Stressのそれより小さいことが分かります。これらの結果は、フィットアプローチがMax_Dispについては良好に機能しているものの、Max_Stressについてはあまり効率がよくないことを示しています。