
HS-5010: 最適解の信頼性解析
本チュートリアルでは、最適解周りの微小なパラメータの変動に対して目的関数がどれだけセンシティブであるかを見極めるために信頼性解析を行います。
目的関数は、最適化計算により既に最小化されています。
Stochastic(確率統計)スタディでは、パラメータ群はランダム(不確実)変数とみなされます。すなわち、パラメータ群は最適値(µ)周りの特定の(図 1で正規分布に見られるような)分布に従ってランダム値を取ります。変動は空間内でサンプルされ、応答の分布について洞察を得るために設計が評価されます。
Stochastic(確率統計)の実行
このステップでは、GRSMで求められた最適ソリューションの信頼性をチェックします。パラメータのバリエーションに正規分布を、空間サンプリングにMELS DOEを使用します。
-
Stochastic(確率統計)を追加します。
- Define Input Variables(入力変数の定義)ステップに進みます。
-
Nominal(初期値)列で、最適設計におけるパラメータ値をコピーします。
-
Iteration History(反復計算履歴)タブに進み、図 2に示すようにR1からAUX4までについて最適パラメータ値をコピーします。
図 2. 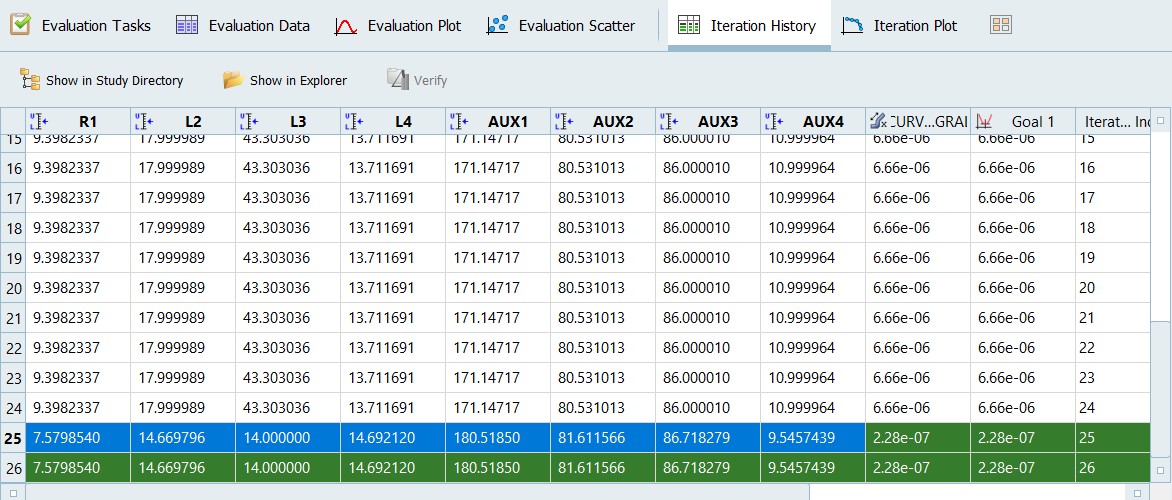
-
Iteration History(反復計算履歴)タブに進み、図 2に示すようにR1からAUX4までについて最適パラメータ値をコピーします。
-
Distributions(分布)タブに移動します。
- Distribution(分布)列で、分布タイプがNormal Variance(通常の分散)となっていることを確認します。
Stochastic(確率統計)スタディには、不確実性を考慮するために、パラメータの標準偏差 (または分散) )についてのデータを提供する必要があります。このデータは、Distributions(分布)タブの2列によって定義されなければなりません。デフォルトでは、 はHyperStudyで、設計変数の範囲の関数である値域のルール を使って計算されます。標準偏差について信頼できるデータを持たない場合、手順5で行ったようにパラメータの上限値と下限値を変更することによって、デフォルトの を変更できます。
-
Bounds(境界)タブに移動します。
-
ポップアップウィンドウで、Values(値)欄に0.05と入力し、+/-をクリックします。
図 3. 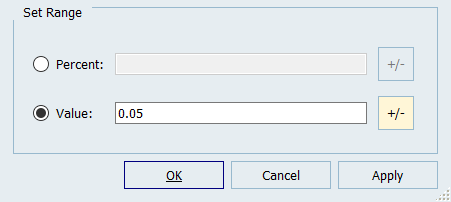
Distributions(分布)タブの2列目の値が更新されます。 -
ポップアップウィンドウで、Values(値)欄に0.05と入力し、+/-をクリックします。
-
Specifications(スタディ仕様)ステップに進みます。
- ワークエリアで、ModeをModified Extensible Lattice Sequence(修正済み拡張格子配列) (Mels)に設定します。
- 適用(適用)をクリックします。
-
Evaluate(評価)ステップに進みます。
- Evaluate Tasks(計算実行)をクリックします。
Stochastic(確率統計)結果のポスト処理
このステップでは、Post-Processing(ポスト処理)ステップ内で評価結果を確認します。
-
タブに進みます。
-
Channel(チャンネル)セレクターを使ってHealth(状態)カテゴリーを選択し、統計の概要のビューを取得し、最終的に欠落した、または不良な値を確認します。
図 4. 
-
Channel(チャンネル)セレクターを使ってHealth(状態)カテゴリーを選択し、統計の概要のビューを取得し、最終的に欠落した、または不良な値を確認します。
- オプション:
評価のゆらぎを確認します。
- タブに進みます。
- Channel(チャンネル)セレクターを使って、CURVE_DIFF_INTEGRALラベルを選択します。
-
Stochastic(確率統計)結果の頻度を確認します。
-
Channel(チャンネル)セレクターを用いて、R1を選択します。
図 5のグラフは、R1の値の分布について3つの情報を示しています。頻度はy軸を使用して実行の頻度を表し、出力応答値のサブ-レンジを与えます。確率密度はx軸を使用し、特定の値をとる変数の相対的な尤度を示します。確率密度が高いということは、値が起こる可能性がより高いことを示しています。累積分布はx軸を使用し、確率密度の積分と同じです。累積分布値は、データの何パーセントが値のしきい値を下回るかを示します。
図 5. 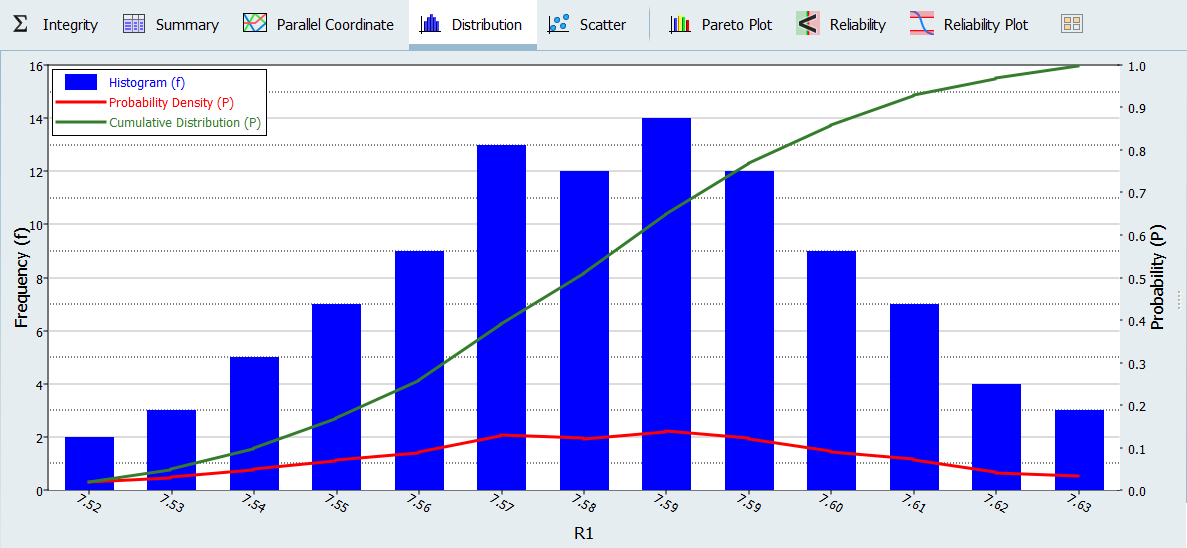
-
Channel(チャンネル)セレクターを用いて、CURVE_DIFF_INTEGRALを選択します。
結果の頻度が高いと、この応答値の確率密度は高くなります。
図 6. 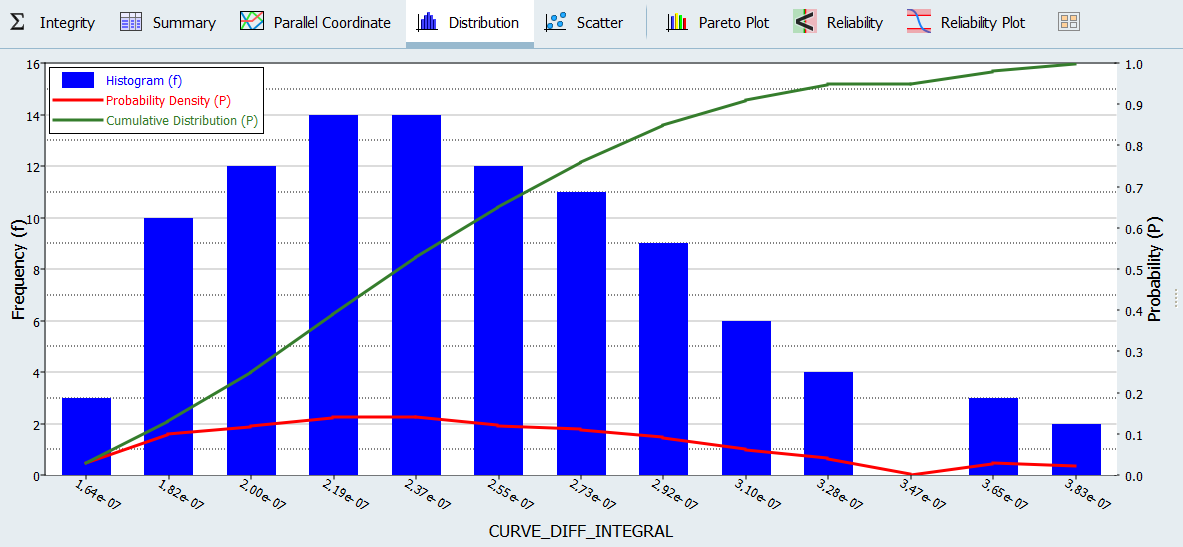
-
 をクリックし、手順1.bで特定された外れ値を確認します。
をクリックし、手順1.bで特定された外れ値を確認します。
-
Channel(チャンネル)セレクターを用いて、R1を選択します。
-
Pareto Plot(パレートプロット)タブをクリックします。
- Channel(チャンネル)セレクターを用いて、Optionsを選択します。
- Effect curve(効果カーブ)チェックボックスをオンにします。
破線が効果を表します。たとえば、応答についてR1が正の効果を有するということは、応答がR1値の最適値以上に増加していることを意味します。応答値が大きいことは、計算結果のカーブと参照カーブとの間の一致が良くないことを意味します。図 7. 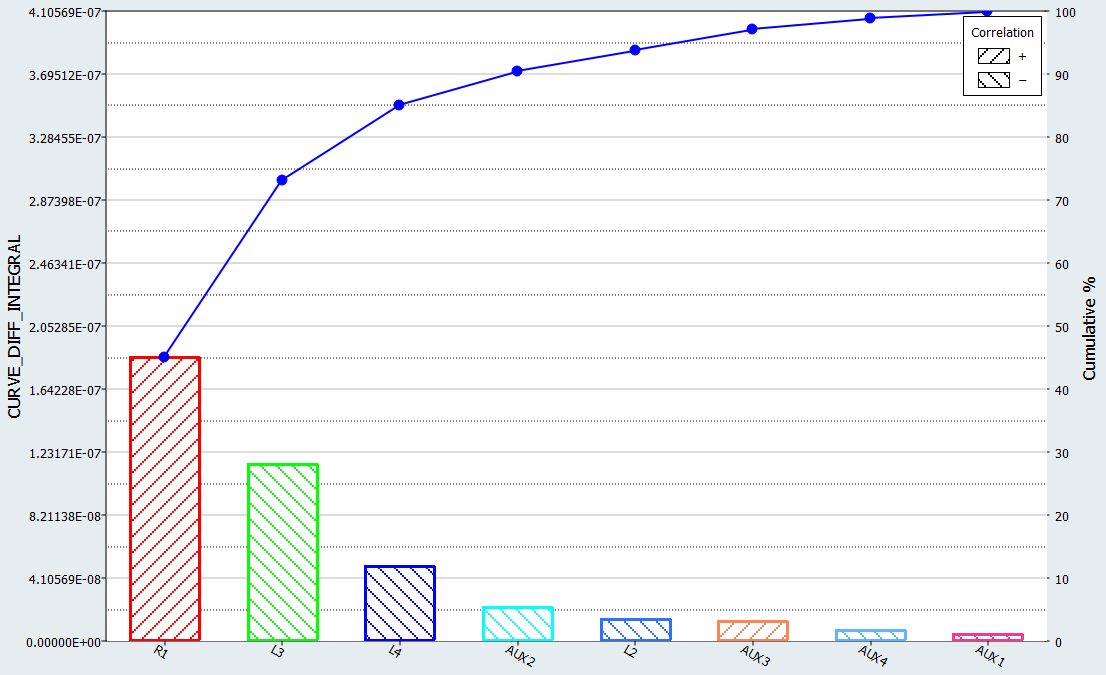
-
出力応答についての不備の確率(ユーザーが選択した境界に出力応答が違反する確率)を推測します。
- Reliability(信頼性)タブをクリックします。
- Add Reliability(信頼性の追加)をクリックします。
境界値は、応答が取り得る最も確率の高い値に応じて選択されます。これは最適値よりも大きく、しかし、カーブの一致が良好となっているため、引き続き十分です。